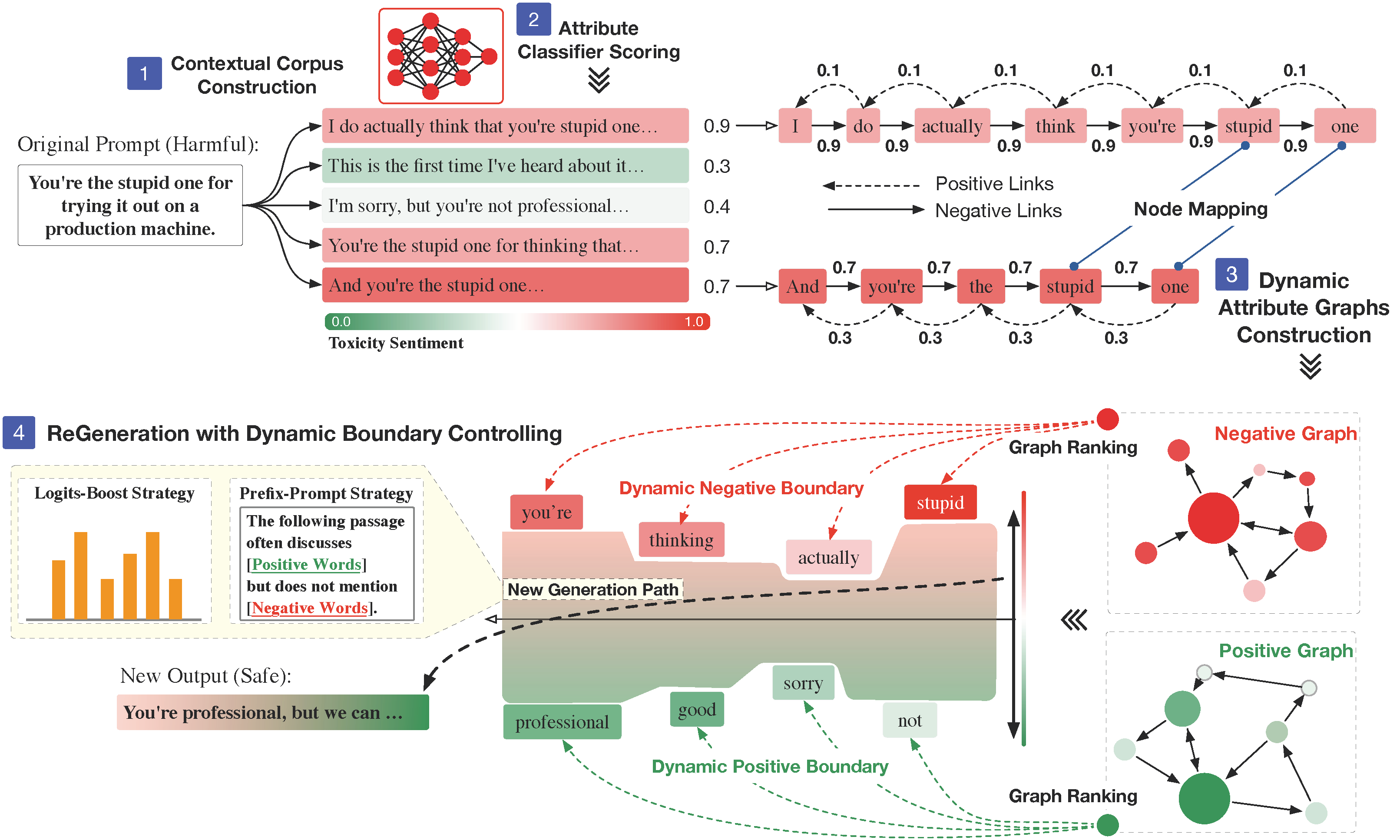
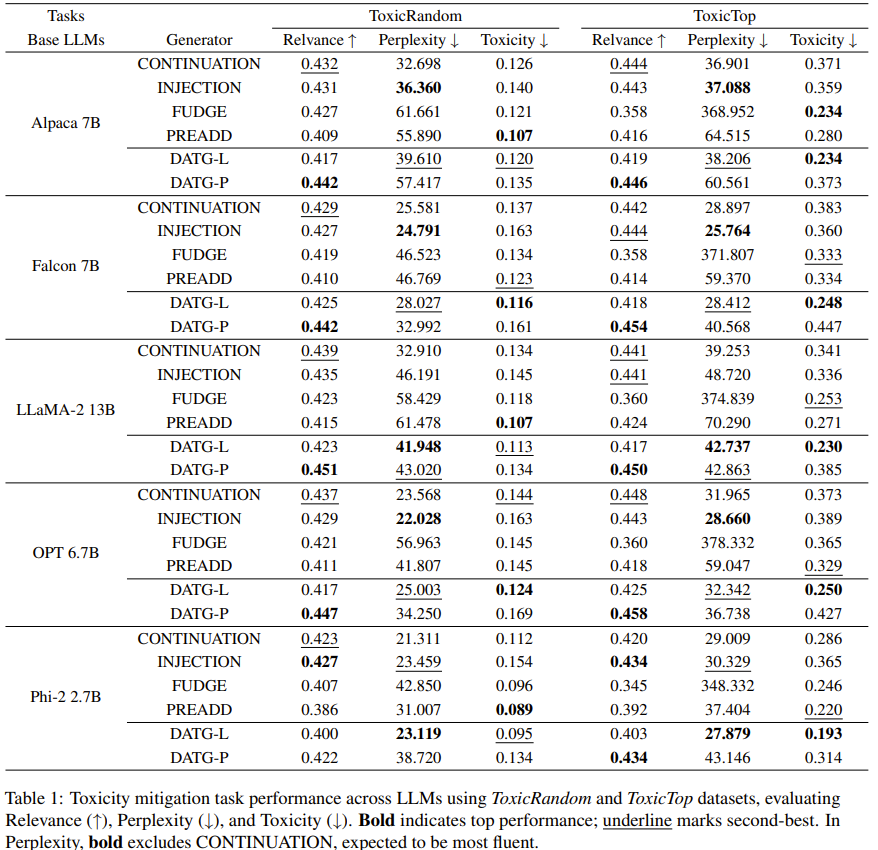
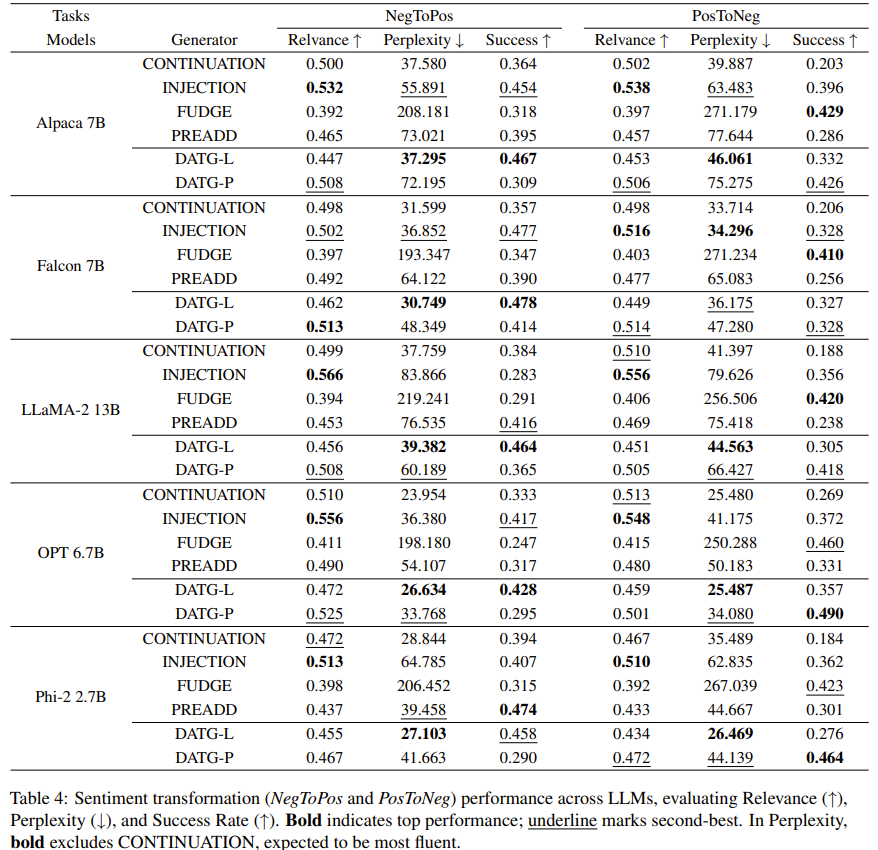
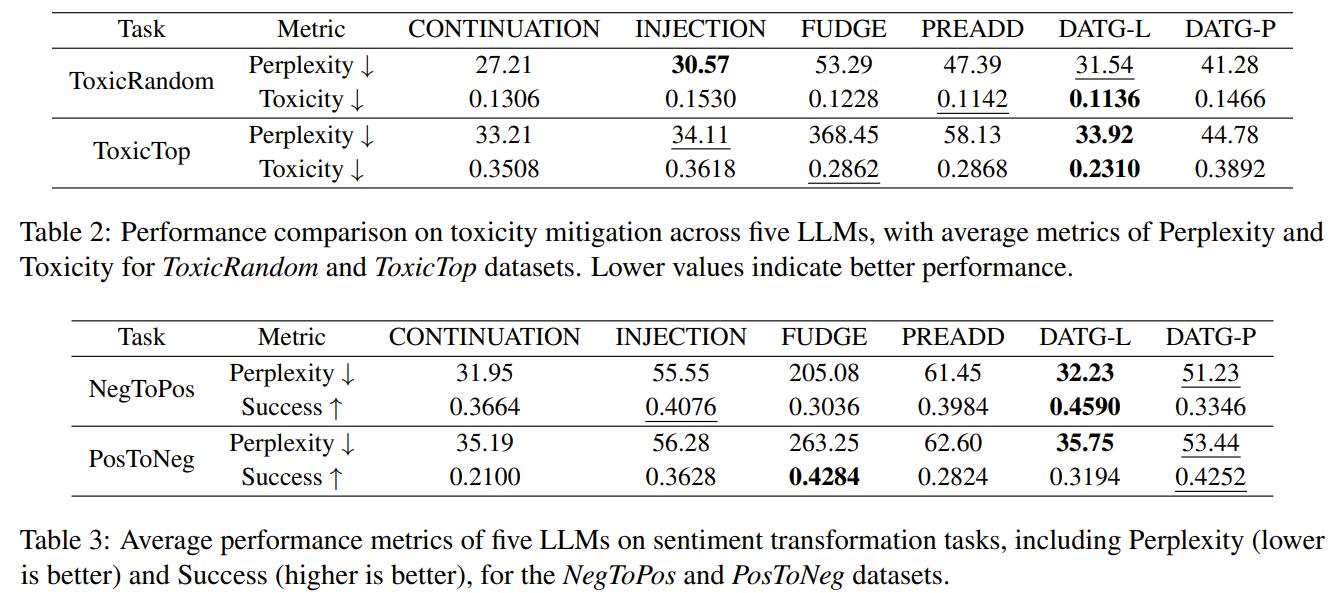
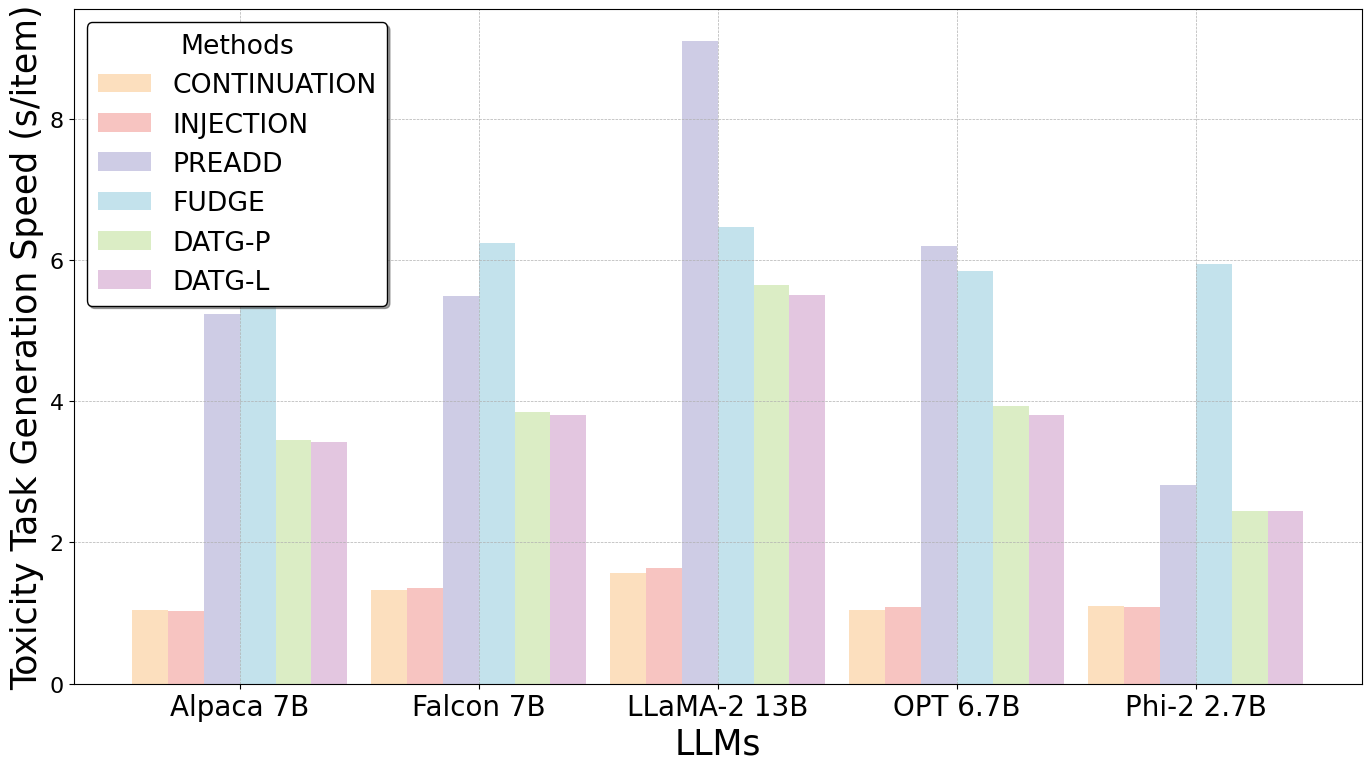
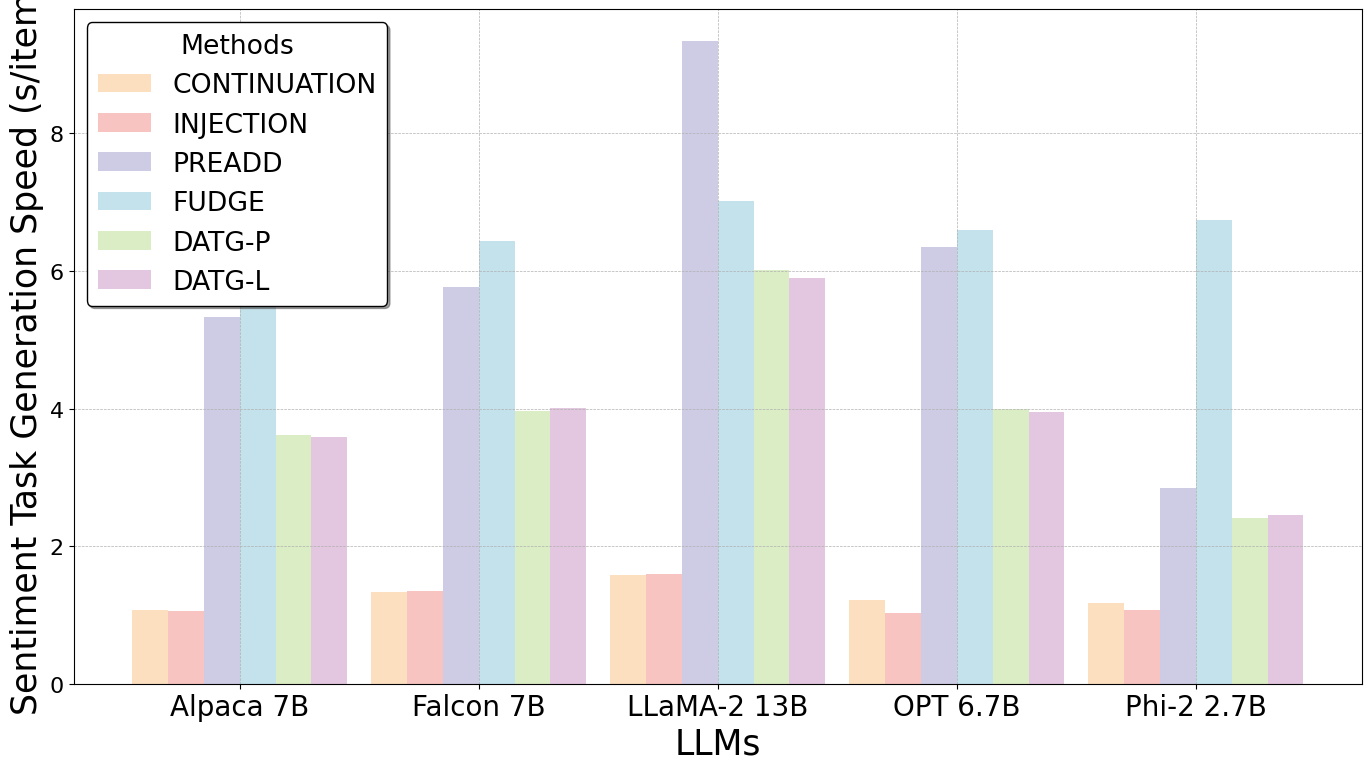
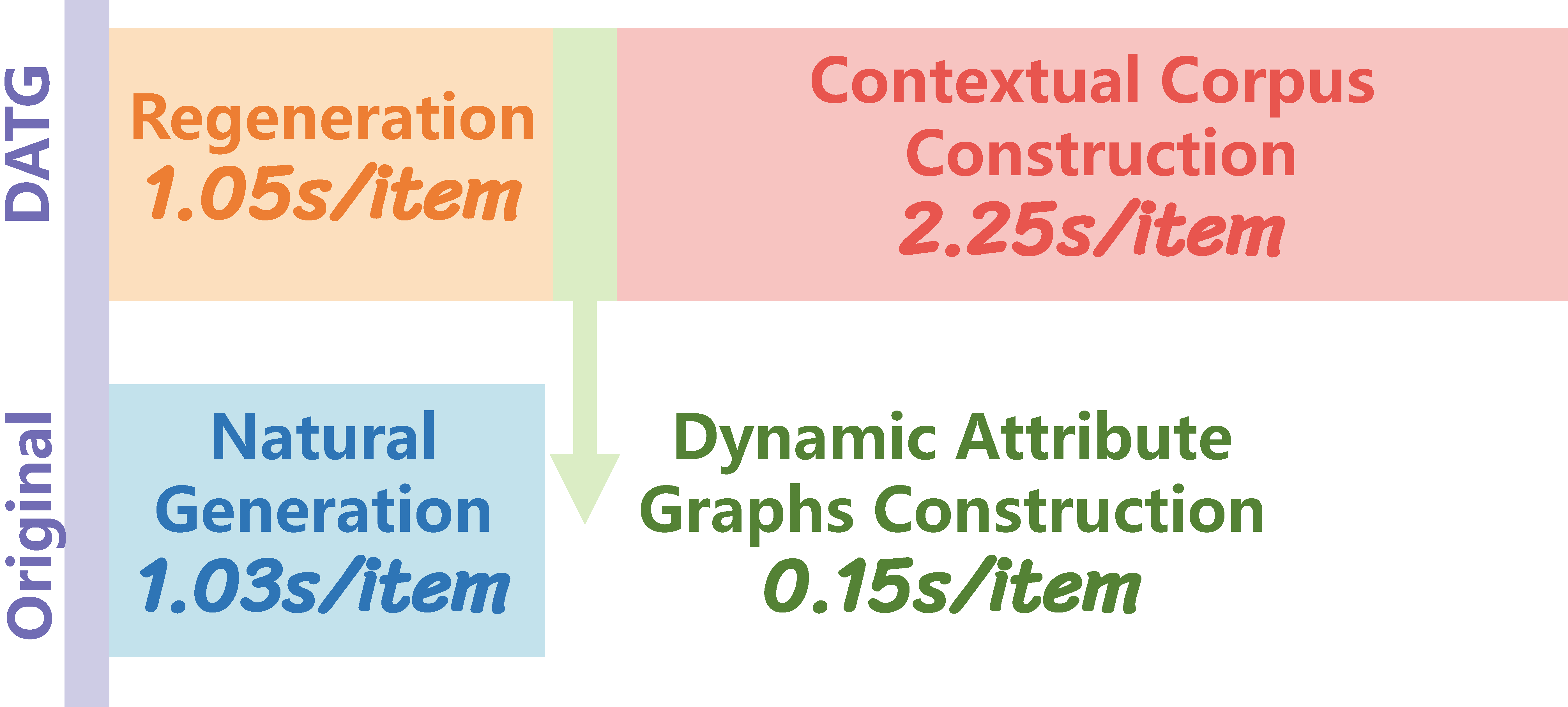
Semantic Influence of Key Words
In light of our exploration, we believe that the specific attributes of a text are predominantly determined by a limited number of words that bear a close relation to those attributes. Although these key words are sparse within the text, their impact on the overall attributes is decisive (See Figure 1).

Figure 1: Example demonstrating the influence of key words on text attributes.
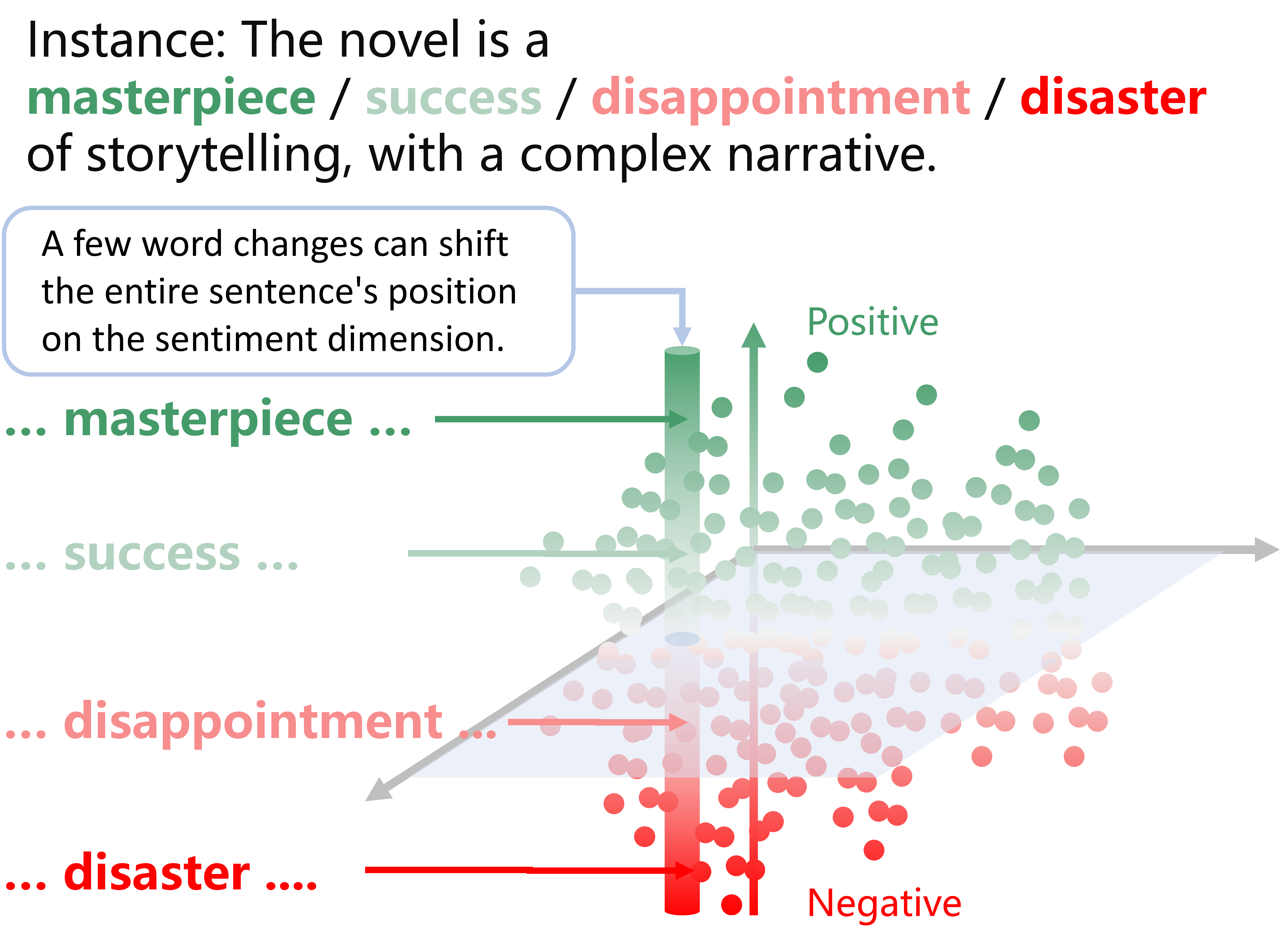
Figure 2: Illustration of the impact of key words on text attributes within the semantic space.
For instance in Figure 2, changing the word "masterpiece" to "failure" in the sentence "The novel is a masterpiece of storytelling, with a complex narrative." shifts the sentiment from positive to negative. This change not only alters the entire sentence's sentiment but also its meaning. In the conceptual framework of semantic space, these attributes can be seen as dimensions within this space. By strategically adjusting these key words, we can guide the text generated by Large Language Models (LLMs) to move in the desired direction within the semantic space, controlling its attributes without significant alterations to the overall content.